환경 : Python 3.10
사용 라이브러리 :
beautifulsoup4 (4.10.0)
requests (2.26.0)
매주 로또 당첨번호를 확인하고 사용하고 있는데 이 패턴을 자동화 하고 싶어 작성하였습니다.
먼저 로또 당첨번호를 확인하기 위해 동행복권 사이트로 이동합니다.

메인 화면 좌측에 당첨번호가 보이지만 해당 회차만 확인 할 수 있습니다.
이전 회차 당첨번호를 확인하기 위해 아래로 이동하였습니다.
'당첨결과 > 회차별 당첨번호'
이동한 페이지는 아래와 같습니다.
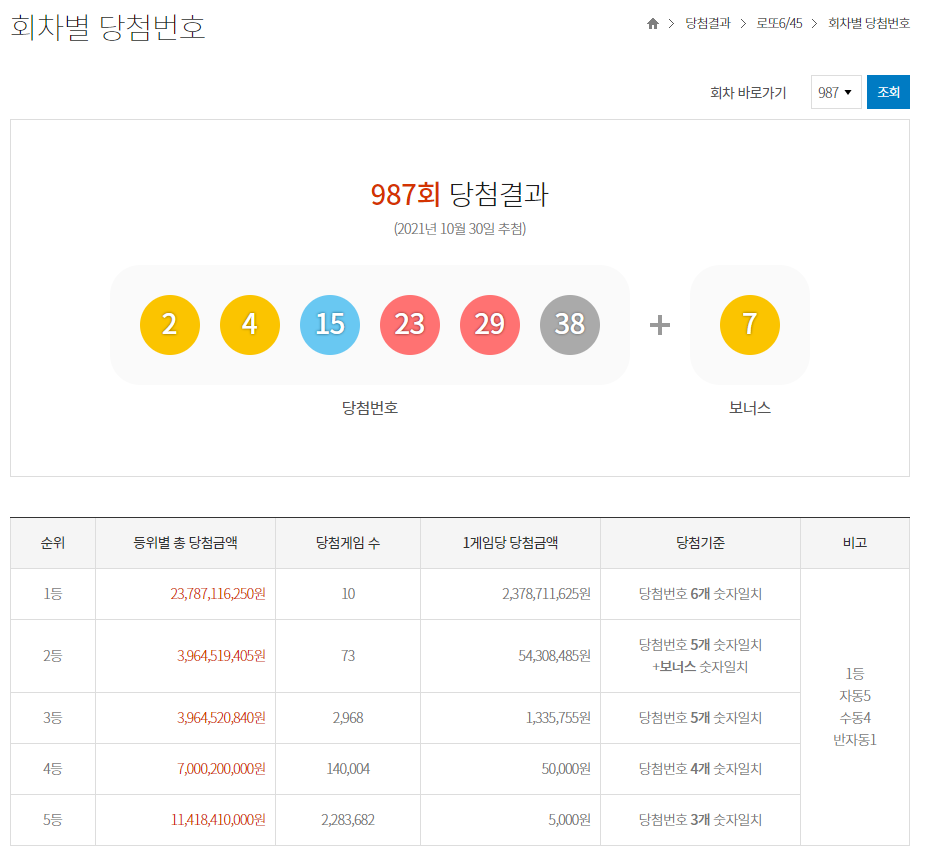
위 페이지에서 회차, 당첨번호, 당첨금액 등을 확인 할 수 있습니다.
구현하고자 하는 것은 이번주 당첨번호를 불러와 당첨번호 파일에 이어서 붙여넣기를 하는 것인데
한번에 여러회차에 대한 정보를 호출할 필요도 있을 것 같습니다.
해당 페이지에서 986, 985, ... 등 이전 회차 번호도 확인하기 위한 URL을 파악해보겠습니다.

회차를 선택하고 조회버튼을 누르면 해당 회차의 당첨번호를 조회하는 동작을 하므로 조회 버튼에 대한 검사를 진행하였습니다.
우 클릭 후 검사
href값에는 javascript.void(0)이라고 하는 #과 같은 역할을 하도록 할당되어있습니다.
그럼 id를 통해 자바스크립트가 동작하는 것이라고 생각하여 id를 검색해보았습니다.

#searchBtn을 클릭하면 search 함수가 호출되도록 작성되어 있습니다.
search함수는 위에 구현되어있고 POST 메소드로 'gameResult.do?method=bywin'을 호출합니다.
그럼 POST메소드에 담기는 데이터를 확인해보겠습니다.


검사 팝업에서 네트워크 탭으로 이동한 뒤 조회버튼을 클릭해주면 위의 2번째 캡처화면과 같이 표현됩니다.


우측에 요청 URL의 정보도 나오고 아래로 스크롤을 내리면 양식 데이터라는 부분에 POST에 담긴 데이터 작성되어 있습니다.
POST에 담기는 데이터로 'dwrNo', 'drwNoList'가 있는 것을 확인하였습니다.
다음 글에서 파악 주소와 셀렉터를 확인하여 파이썬 소스코드를 작성하고 웹 크롤링을 해보겠습니다.
'Dev' 카테고리의 다른 글
| AWS General Immersion Day 후기 : AWS Network(1) (0) | 2021.11.04 |
|---|---|
| AWS General Immersion Day 후기 : Overview (0) | 2021.11.03 |